

About dbt:
dbt is a transformation engine using code-first software engineering principles. Basically tons of text files defining what to transform and how. The good thing is that it comes with many features out of the box, such as documentation, lineage and testing. Ther are also many challenges, such as it can become very labor intensive and sometimes cost intensive, if traditional modelling techniques and a common sense is used.
We aim to leverage the benefits of dbt and hopefully diminish some of the disadvantages
Main benefits:
- orchestrate whole pipeline at one place
- trigger dbt cloud jobs, run dbt against your DWH or within Keboola platform
- store dbt artifacts and run stats in one place
- explore dbt docs on one click
- have a local developer environment with cloned data in one command
We are supporting three major use cases from the day one:
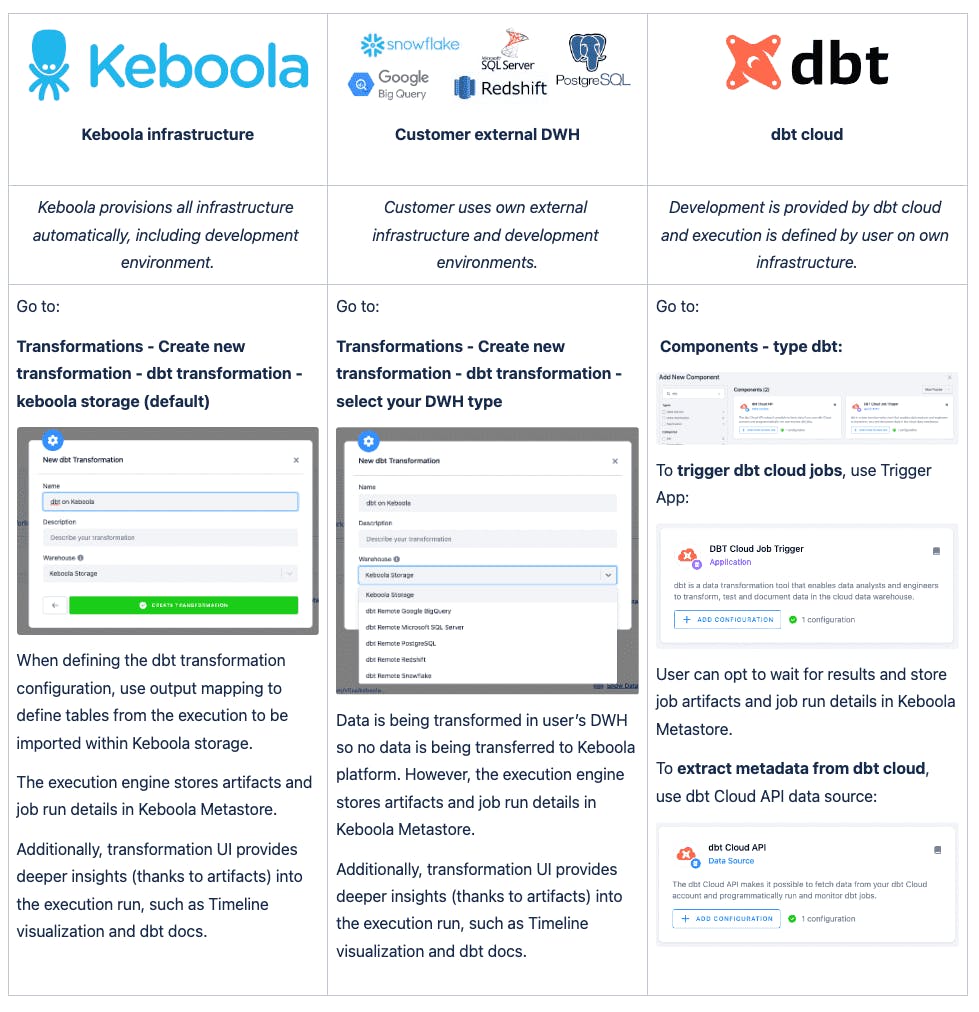
We will be posting more informations and videos to help users to navigate new features.
How to get hands on it?
To make dbt work, we need two new projects features (that are cool by itself):read-only-storage and artifacts All new PAYG projects have those features activated by default. All existing projects can request the activation through support request.