

I would like to share with you some advanced tips on how to modify the behaviour of Event Triggered Orchestration. As you know, the event trigger is very useful when you need to trigger a downstream process only when there is some import on a specific table. Current orchestration trigger reacts on any import event, which in practice means that it may trigger even if there is no data coming in within that import event. A typical example is a Transformation that creates an empty table. If there is an output mapping for that table, the import event will be always generated.
It is very often that we need to modify this behaviour to trigger orchestration only when the monitored table is actually updated or even to react to some more complex condition. We can achieve this even using the current event trigger using a combination of a Python transformation and a “trigger” table that we will use to react on in our event trigger.
Example conditional trigger process:
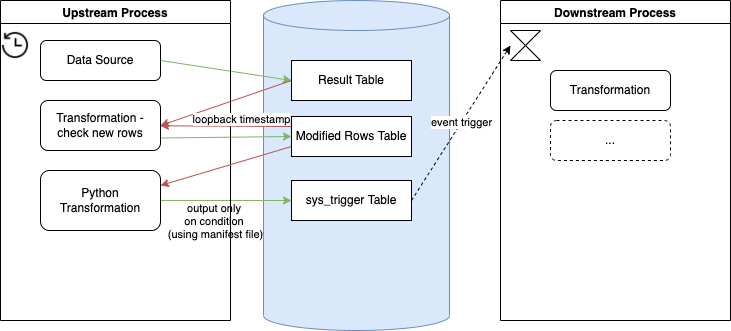
The above process consists of following steps:
- Extract data to Result Table
- Run Transformation that takes
Result TableandModified Rowstable on input. FilterResult Tabledata by last modified timestamp from previous run (Mofified Rowsloopback) and overwrites the Modified Rows table with the result. - Python Transformations checks whether the
Modified Rowscontains any data and if it does it outputs row tosys_triggertable - Downstream Process is triggered.
(Alternatively you can skip the step 2 completely and just load data changed in last X into the Python transformation.)
Example Python Transformation
The key is to generate the import event only when a certain condition is met. This can be achieved using Python transformation with no output mapping but outputting tables using the table manifest instead. You do not need to understand the details about output manifests though. We provide a convenient Python library that abstracts this for you and which is by default present in all Python workspaces / transformations.
Example Python Code:
import csv
from datetime import datetime
from keboola.component import CommonInterface
ci = CommonInterface()
new_rows_table = ci.get_input_table_definition_by_name('modified_rows.csv')
with open(new_rows_table.full_path, 'r') as inp:
inp.readline()
lin = inp.readline()
has_data = len(lin)
if not has_data:
print("No new rows")
exit(0)
result_table_id = 'out.c-sys_trigger.trigger_systable'
out_table = ci.create_out_table_definition('data.csv', destination=result_table_id, incremental=True)
print(has_data)
now = datetime.now()
with open(out_table.full_path, 'w+', newline='') as out:
writer = csv.DictWriter(out, fieldnames=['timestamp', 'event'], lineterminator='\n', delimiter=',')
writer.writeheader()
writer.writerow({"timestamp": now.strftime("%H:%M:%S"), "event": "success"})
print('Triggering')
# finally write result manifest
ci.write_manifest(out_table)